4 Errores de arquitectura que cometí construyendo un agente ReAct desde cero
Cuando vi OpenClaw explotando en enero — Jensen Huang hablando de "el software más importante del mundo", filas en China para instalarlo — lo primero que hice fue instalarlo y ponerlo a correr.
Funcionaba. Pero rápido empecé a querer entender qué pasaba internamente: por qué a veces inventaba resultados, por qué se lentificaba con muchas skills, cómo tomaba decisiones realmente. Así que construí Jada desde cero con el mismo concepto, mi propio código, para entender los internos de verdad.
Lo primero que alguien pregunta es: ¿tiene sentido construir desde cero si ya existe OpenClaw?
Depende del caso de uso. Si necesitas desplegar un agente para un cliente en dos semanas, usar un framework con buena comunidad tiene todo el sentido. Donde sí vale construir desde cero es cuando tienes restricciones que el framework no puede absorber — un servidor con 2GB de RAM donde PyTorch solo no cabe, requisitos de seguridad muy específicos sobre qué comandos puede ejecutar el agente, routing multi-modelo que el framework abstrae demasiado — o cuando quieres entender los internos antes de adaptar uno para producción real, que fue mi caso.
Lo que encontré construyéndolo aplica a cualquiera que esté usando OpenClaw, Agno, LangChain o cualquier framework de agentes hoy.
La arquitectura base: ReAct + Coordinator Pattern
Jada usa el patrón ReAct: el agente recibe un mensaje, razona sobre qué tool necesita, la ejecuta, observa el resultado, y responde. En lugar de adivinar, trabaja en un loop de razonamiento y ejecución. Eso es lo que hace que un agente realmente ejecute cosas en lugar de inventar que las ejecutó.
La arquitectura base la saqué de la documentación de patrones de diseño de agentes de Google Cloud — específicamente el Coordinator Pattern: un solo punto de entrada que descompone el request y dirige hacia las herramientas correctas. Sobre esa base vinieron los errores.
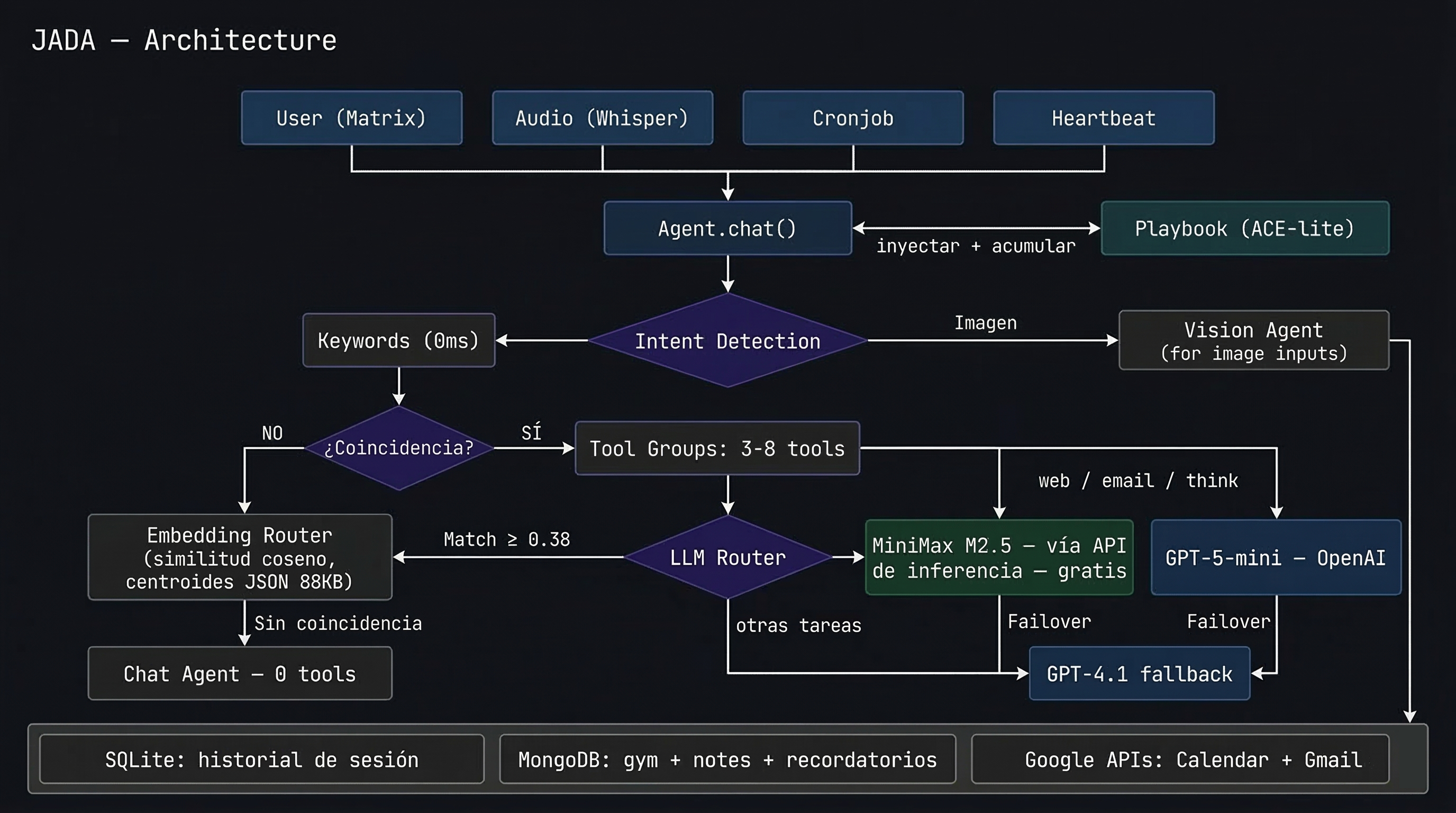
Vista general de la arquitectura: un coordinador central, detección de intención y routing por grupos de tools y modelo.
Error 1: mandar las 46 tools al LLM en cada request
Jada tiene 46 tools distribuidas en 11 grupos: correo, calendario, gym, notas, recordatorios, TV Samsung, búsqueda web, Reddit, visión, shell, almacenamiento. Al principio se las mandaba todas al LLM en cada request.
El modelo respondía "nota guardada ✅" sin haber llamado ninguna función.
Liu et al. (Stanford, 2024) demostraron que los LLMs tienen atención en forma de U: recuerdan bien el inicio y el final del contexto pero lo del medio desaparece. Con 46 definiciones de herramientas en el prompt, la mitad cae en esa zona ciega y el modelo empieza a improvisar.
La solución: router de tres capas
Capa 1 — Keywords. Si el mensaje contiene "correo", "gym" o "tv", carga solo ese grupo de tools. Cero latencia, sin llamadas a APIs. Resuelve el 80% de los casos.
Capa 2 — Embeddings semánticos (fallback). Cuando las keywords no alcanzan — alguien escribe "qué tengo pendiente hoy" sin mencionar calendario — entra el router semántico.
El mecanismo es simple: por cada grupo de tools se generan embeddings de frases representativas y se promedian en un centroide del grupo, que se guarda en disco. En runtime, la query del usuario se embede y se compara por similitud coseno contra los 11 centroides. El grupo más cercano gana.
El cálculo de centroides cuesta una sola llamada a una API de embeddings, una sola vez. Después es leer un JSON de 88KB. Eso reemplazó una librería local que consumía 800MB de RAM con PyTorch incluido — y el resultado es el mismo.
Capa 3 — Fallback al agente completo. Si ningún centroide supera el umbral de similitud, se cargan todos los grupos. Raro, pero existe como safety net.
Error 2: un solo modelo para todo
Al principio todo pasaba por el mismo LLM. Responder "qué hora es" y analizar un PDF de 40 páginas no deberían costar lo mismo ni esperar en la misma fila.
Implementé routing multi-modelo basado en el grupo de tools que necesita el mensaje:
- Conversación rápida y tools simples → modelo liviano y barato
- Búsquedas web, correo, razonamiento profundo → modelos con ventana de contexto larga, disponibles gratis a través de APIs de inferencia en la nube
- Visión → modelo especializado, también gratuito
- Si el modelo primario falla o hace timeout → failover automático al modelo de pago
Esto no es optimización prematura. Es que los modelos no son iguales para todo, y pretender que sí sale caro, lento, o ambos.
Error 3: comprimir el system prompt para ahorrar tokens
Instinto común cuando el agente se lentificó: acortar instrucciones, resumir historial, eliminar reglas que parecían redundantes.
El agente empezó a olvidar comportamientos que le había enseñado y a volverse genérico.
El ACE Framework (Stanford + SambaNova, oct 2025) documenta exactamente esto: "brevity bias" y "context collapse". Cuando comprimes instrucciones iterativamente, el modelo pierde especificidad del dominio y colapsa a patrones promedio. Lo que parecía optimización razonable destruye la identidad del agente.
Lo que sí funcionó fue comprimir los outputs de las herramientas, no las instrucciones. Un resultado de búsqueda web trae 15,000 tokens; truncado a 120 caracteres por snippet ahorra un 30% de tokens sin tocar el comportamiento.
La regla es simple: comprimir identidad mata al agente. Comprimir ruido lo mejora.
Error 4: múltiples agentes especializados sin estado compartido
La decisión que parece lógica al principio: un agente para chat, uno para funciones, uno para visión. Cada uno especializado en su dominio.
En producción, cuando pedía un recordatorio después de diez minutos de conversación, el router mandaba al agente de funciones que no sabía nada de lo que había pasado antes. Un día de debugging para encontrar la causa: historiales de sesión completamente separados entre agentes.
Esto está documentado en los patrones de diseño de agentes de Google Cloud como el trade-off principal del enfoque multi-agente: más llamadas al modelo, más latencia, y el estado no se comparte a menos que lo diseñes explícitamente. La recomendación de Google es empezar con un solo coordinador.
Eso es exactamente lo que implementé: un orquestador único con historial compartido en SQLite. El problema desapareció.
Lo que no estaba en el plan y cambió el resultado
Playbook incremental: el agente aprende en producción sin reentrenamiento
El problema que esto resuelve es específico: un agente típico comete el mismo error hoy que cometió la semana pasada porque no tiene mecanismo para acumular lo que aprendió. Fine-tuning resolvería eso pero cuesta dinero, tiempo y expertise.
El ACE Framework propone una alternativa: tratar el context window como un "playbook" que crece incrementalmente con cada interacción, en lugar de reescribirse.
La implementación en Jada funciona así:
- Después de cada interacción con tools, un modelo corre en background y analiza si hubo algo que aprender — una corrección del usuario, un workaround que funcionó, una preferencia nueva
- Si encuentra algo, hace un append al playbook como un "delta update". Nunca reescribe lo anterior, solo acumula
- Cada entrada se clasifica por importancia (alta/media/baja)
- Ese playbook se inyecta como bullets al system prompt en cada llamada siguiente
- Cuando llega a 50 entradas, las de baja importancia se podan
El modelo que analiza en background es gratuito, así que el costo de aprender es cero.
El paper de ACE muestra +10.6% de mejora en benchmarks de agentes usando este patrón, sin fine-tuning, usando solo feedback natural de ejecución. Un modelo open-source más pequeño igualó a un agente de producción de IBM basado en GPT-4.1 simplemente acumulando contexto bien estructurado.
Motor dual: ReAct para conversación, workflows deterministas para automatizaciones
ReAct es potente pero probabilístico: cada vez que el agente corre el mismo task puede tomar un camino diferente. Para conversación interactiva eso es una ventaja — la flexibilidad es el punto. Para automatizaciones programadas — un brief de correos a las 7am, métricas semanales, notificaciones — esa imprevisibilidad se convierte en problema real. El agente puede alucinar un paso, saltarse una validación, o elegir el camino equivocado sin que nadie se dé cuenta hasta que ya pasó.
La solución fue un motor dual:
- ReAct para conversación interactiva donde la flexibilidad tiene valor
- Workflows deterministas en Python para los cronjobs donde los pasos son fijos
En un workflow determinista el código fuerza la secuencia: leer correos → filtrar por criterio → pasar solo el texto al LLM para que sintetice → enviar. El LLM hace la parte que le corresponde — resumir, redactar — pero no decide el flujo. Eso eliminó completamente los timeouts y resultados inconsistentes en automatizaciones.
El agente tiene dos modos según lo que el contexto necesita.
Referencias
- Liu et al. — Lost in the Middle: How Language Models Use Long Contexts (Stanford, TACL 2024) → arxiv.org/abs/2307.03172
- ACE: A LLM-based Negotiation Coaching System (Stanford + SambaNova + UC Berkeley, oct 2025) → arxiv.org/abs/2510.04618
- Google Cloud — Choose a design pattern for your agentic AI system → docs.cloud.google.com/architecture/choose-design-pattern-agentic-ai-system
- IBM / Marina Danilevsky — AI agents in 2025: Expectations vs. reality (nov 2025) → ibm.com/think/insights/ai-agents-2025-expectations-vs-reality
- OpenClaw → Wikipedia
Conclusión
La conclusión no es que haya que construir desde cero. OpenClaw tiene sentido usarlo. La conclusión es que los problemas de producción de un agente — alucinaciones de tool calls, costo, pérdida de identidad, amnesia entre agentes, automatizaciones que fallan silenciosamente — aparecen con cualquier herramienta en cuanto el uso crece. Entender por qué pasan cambia cómo los resuelves.
¿Estás usando OpenClaw o construyendo un agente para tu empresa o para un cliente? Con qué te has topado.